SND Dataset
Introduction
SND Dataset is the partial outcome of my greater research unit on audio classification problems and music information retrieval scenarios.Since the greater research has been completed, the next step would be to address the constructed dataset to the public.
This section focuses on music streaming services and the techniques for extracting audio data from them. In the discusses the ways in which quality control is applied to this data, i.e. whether it is valid and reliable. Finally it highlights the method of storing and cleaning the data so as to ensure at this stage a fairly clean and balanced set. As is well known, in order to solve DL problems, access to large data sets is necessary. Unfortunately, no ready dataset was found to conduct this research. A dataset which on the one hand generalizes the distribution of music, on the other hand has annotations that cover the research objectives. Therefore, for the needs of the research a specially adapted dataset is created, which I analyze in the next section, while mentioning similar examples of such datasets concerning sound and music in particular.
This dataset contains 11k labelled tunes in 9 classes of music genre.The label that describes the music genre has been annotated by users and the tunes have been collected from music streaming services.
Tunes
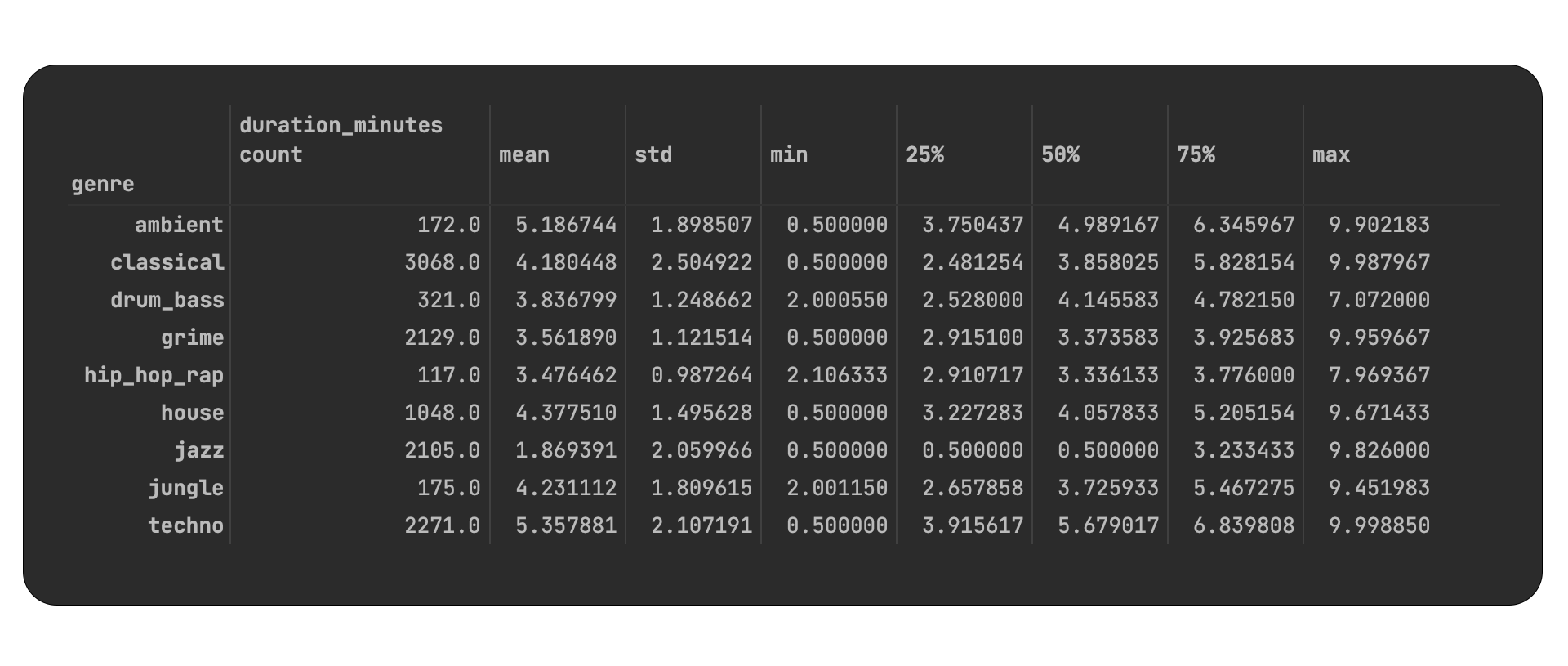
The duration of each sample varies from 1 to 9 minutes long. For further reading go to the statistics section. Each sample is downsampled to mono with a sample rate of 44100 Hz and 32-bit (float) bit depth in wav format.
Data Models
The principal model has been assembled by two relational tables. The first table contains audio metadata and information about each track. The second table contains the transcoding data with audio information and technical specification about the encodings and the formatting of each audio data sample. The dataset has been implemented as a SQL database data model representation and is served by a java spring boot application with an integrated API.
Database Models Diagram
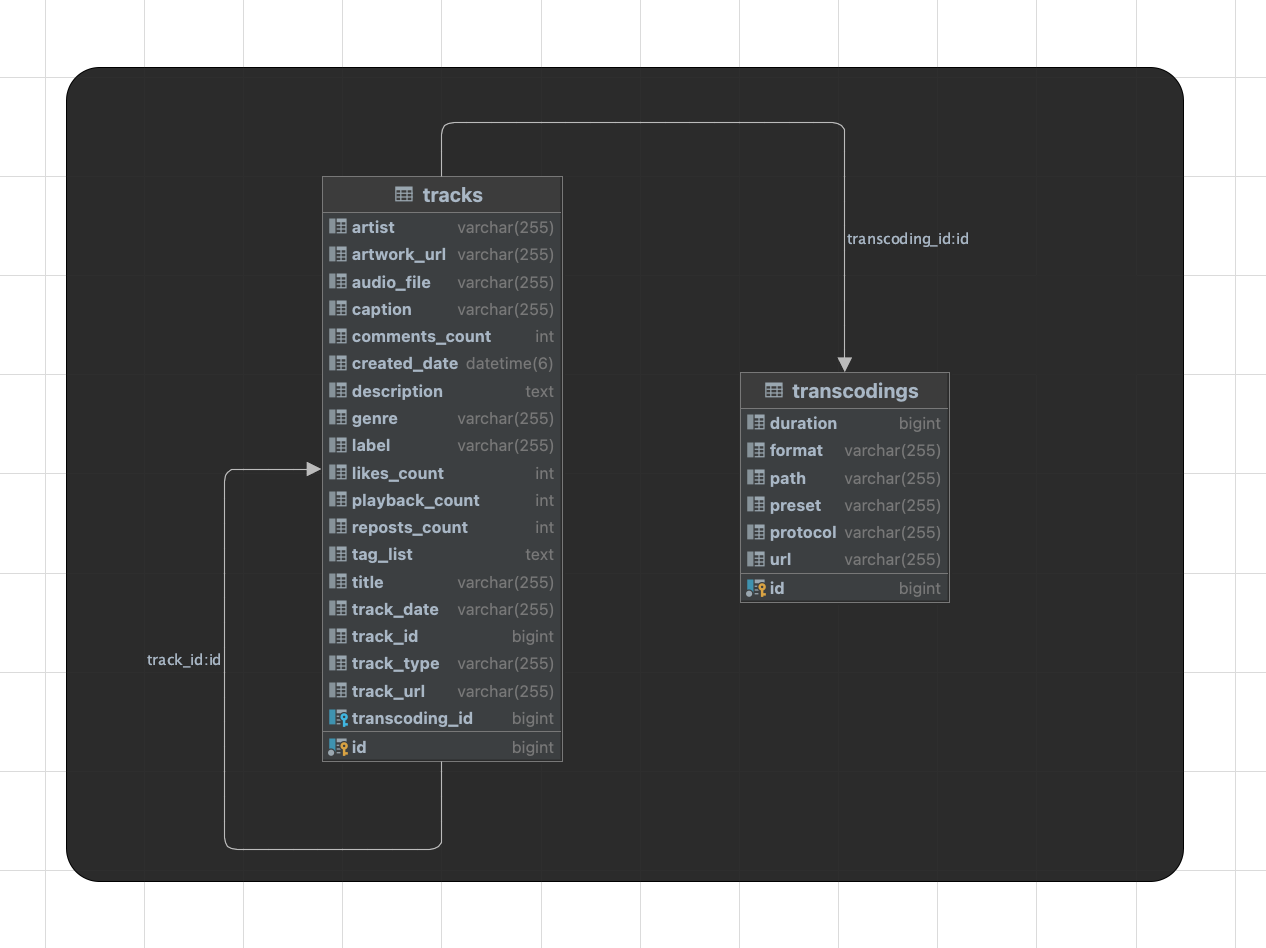
Design Principles
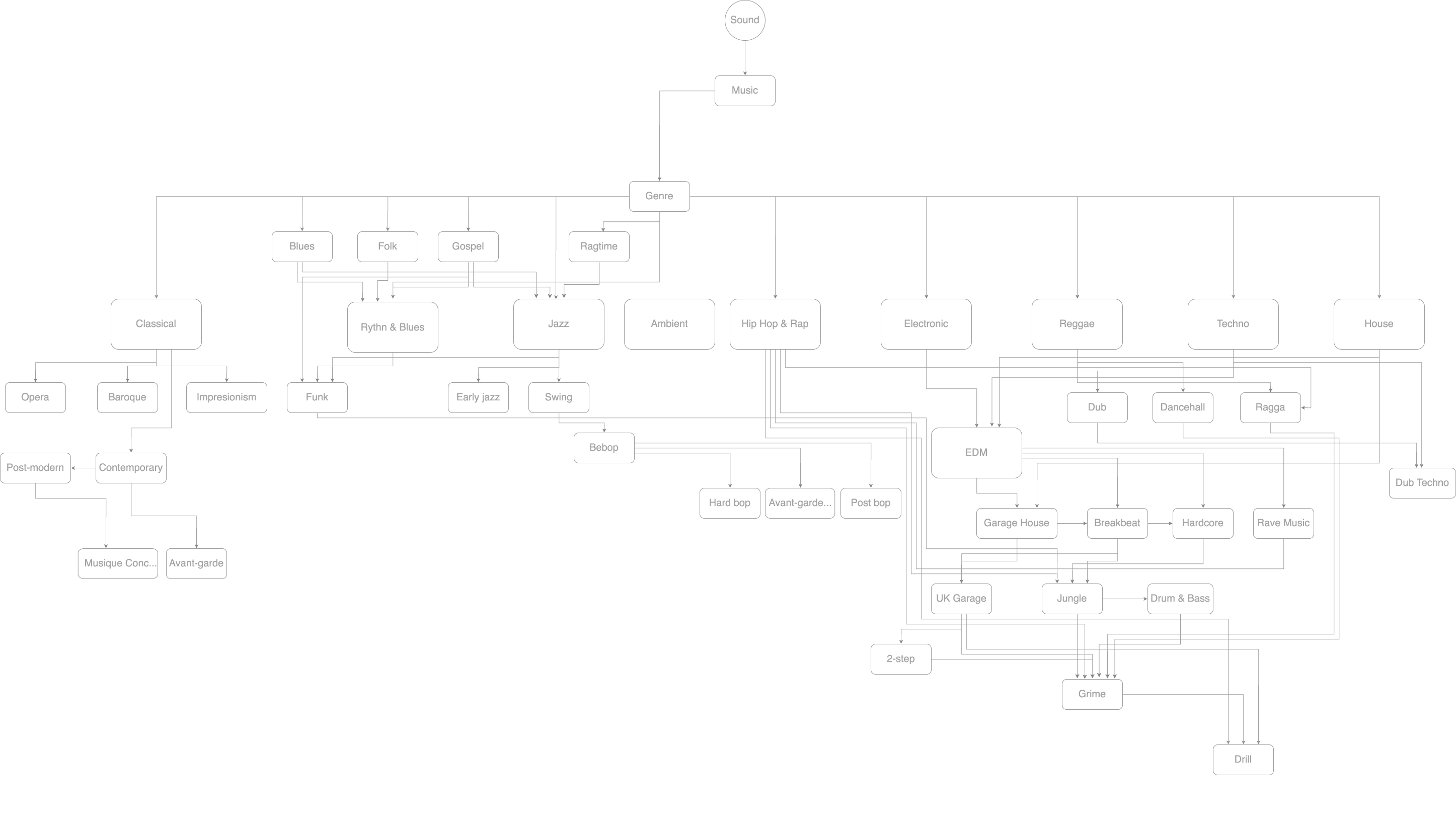
The study around the way music streaming services organise data streaming services inspired the introduction of this concept of the umbrella music genre. Therefore to solve this problem the dataset should be sorted according to a valid value in the music genus class. As I mentioned above as a design principle of creating this dataset, I introduce the concept of hyper genre. Therefore, the annotations have been labelled as hyper genres.
Taxonomy
The current implementation of this dataset has annotated with 1 class which is the music genre column. The music genres are 9 and there is a numeric identifier for each string of genre column.
| Genre | Class ID |
|---|---|
| Grime | 0 |
| Jazz | 1 |
| Classical | 2 |
| Techno | 3 |
| House | 4 |
| Drum & bass | 5 |
| Jungle | 6 |
| Ambient | 7 |
| Hip Hop & Rap | 8 |
Descriptive Statistics
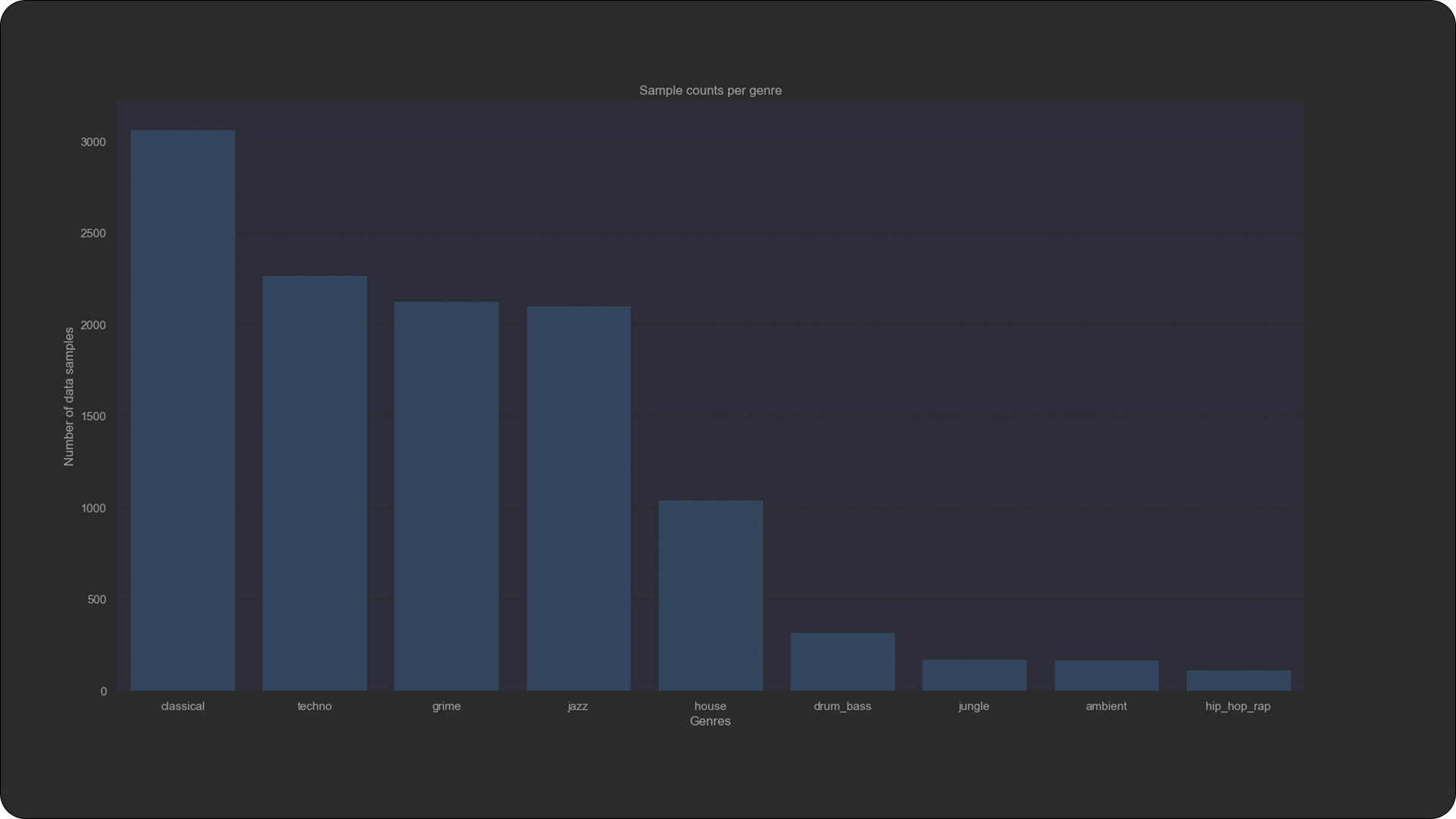
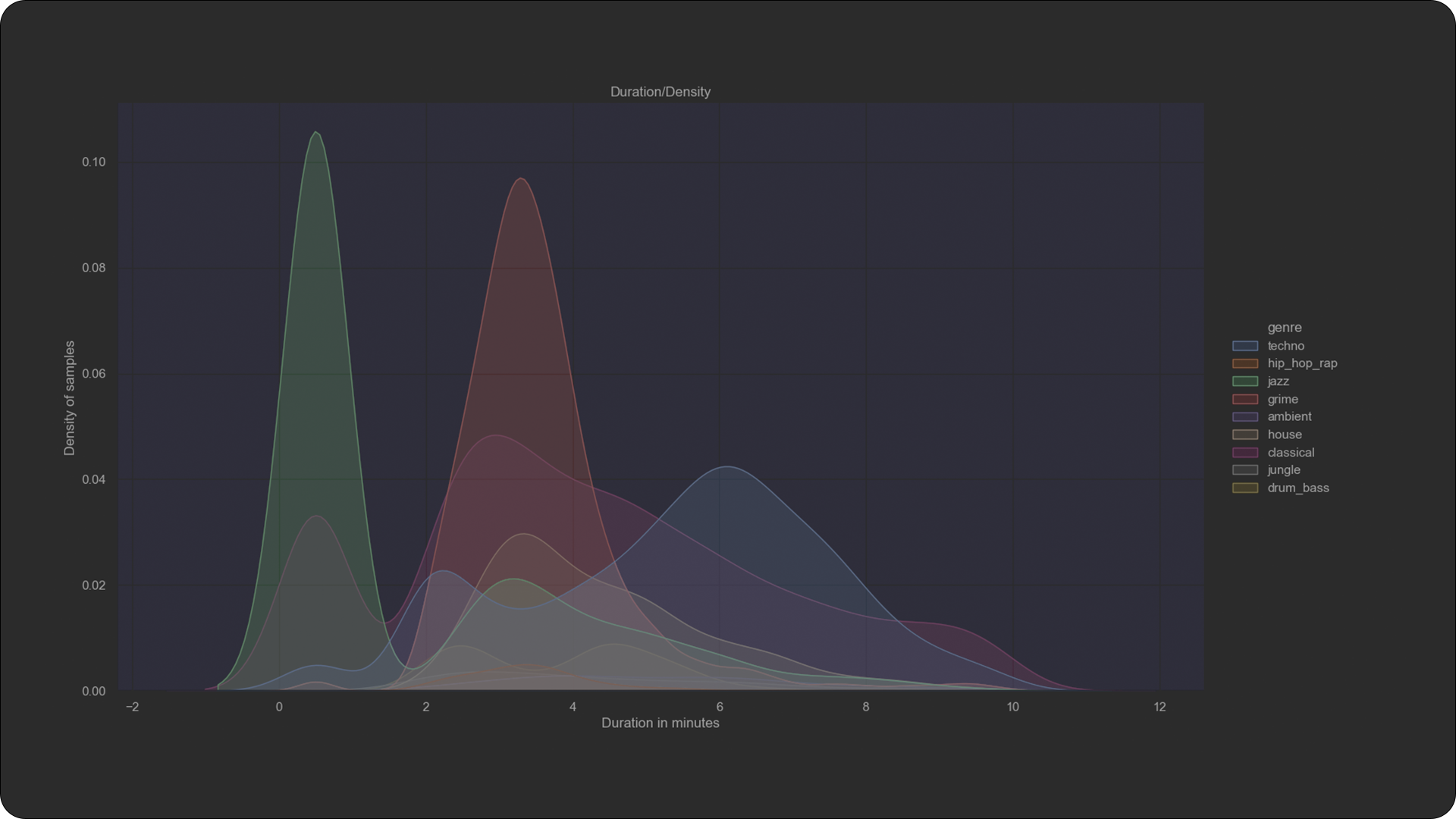
Samples


Future Additions
-
Add 20+ genres
-
Expand hyper genres concept with sub genres enclosures
-
Extract information from tag_list column and create additional classes.
-
Annotate bpm count
-
Annotate key value and label as major or minor scale.