Architecture
CNN001
The methodology I followed to develop the CNN is based on the complexity simplification abstraction process just as I did in the definition of the ACLF problem in the theoretical part. Consequently, the first implementation of the CNN which for consistency I call CNNNetwork, is based on the VGGNet architecture. CNNNetwork.
The first version of this implementation has a fixed size of input variables. The input to the network is a Tensor with three dimensions expressed as Tensor(1, 64, 44). Each audio file is transformed to a duration of one second, and the number of features entering the network for each file of that duration is 2560. The spectrogram image represented by the above Tensor is input through a stack of convolutional layers. This stack consists of four convolutional layers (CONV). Each CONV has a kernel dimension (receptive field) of a 3 x 3 matrix and the convolution step (stride) has the numerical value 1. After each convolutional layer the nonlinearity function of the ReLU model is followed. Then spatial pooling is performed at the end of each CONV using Max Pooling. Max Pooling is performed with a kernel dimension of 2 x 2 with the convolution step (stride) having the numerical value 2. Following the transactional stack is a Fully-Connected (FC) layer which has a channel count of 5,122. The last layer in this architecture is a soft-max layer which becomes the ACLF and classifies the audio files into two classes.
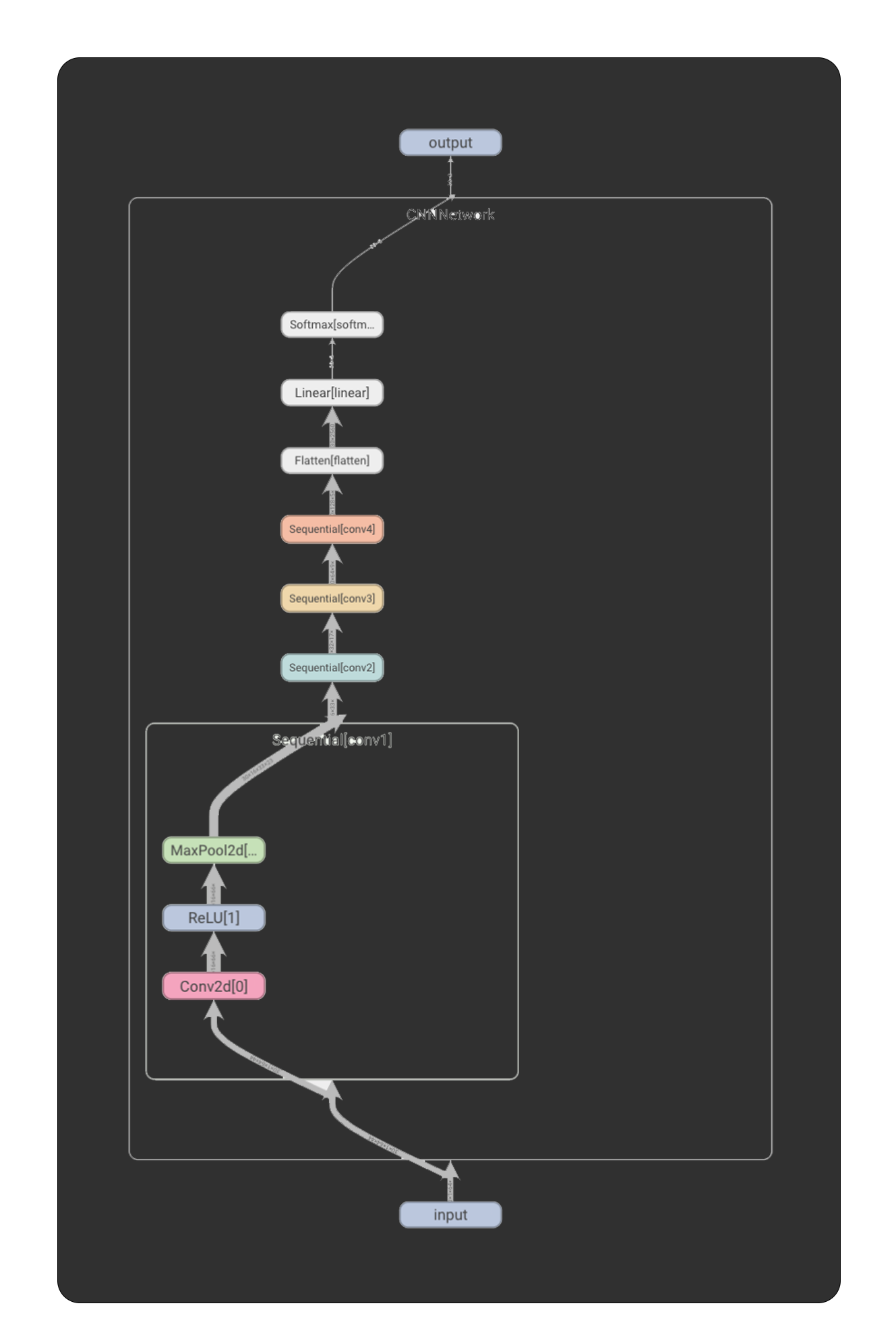
CNN002
The next architectural approach also focuses on the VGG architecture but this time with the implementation of a much deeper model. I will refer to this model as VGGish for consistency. The architectural approach of the VGGish model is based on a publication entitled CNN Architectures for Large-Scale Audio Classification in which they address an Acoustic Event Detection problem. This architecture was created both to test the data on a network with much greater depth, and also to allow the duration of the file to be realized and hence the number of features to be adaptive when they enter the ACLF. VGGish consists of a sequence of six convolutional layers and a sequence of four layers of linear transformations, and each of these is followed by a ReLU nonlinearity function. Each convolutional layer has a kernel dimension (receptive field) of a 3 x 3 matrix with the convolution step (stride) set to the numerical value of 1 just like in CNNNetwork. Max Pooling layers with a kernel dimension of 2 x 2 and the convolution step (stride) set to the numerical value of 2 have been placed in the 1st, 2nd, 4th layers, while an Adaptive Max Pooling layer has been placed in the last one. Then 3 FC layers are placed where each of them is followed by a ReLU nonlinearity function layer
