At this step, it is crucial to analyse some random audio samples from the collected data. This procedure, will help us to better understand our data by visualizing the audio files with various techniques. Furthermore, this analysis aims to extract audio features that will be used later on in the building process of our model.
Audio feature extraction
For audio feature extraction we will implement some methods and functions from the torchaudio (opens in a new tab) python framework. We will try to explore the relationship between common audio features, such as the waveform, with advanced features the torchaudio's API offers For presentation purposes we will present two different examples from the collected data, not yet labeled with aprox 4 seconds length each.
Audio
Jan23_21-00-33-hip-hop-228614956.wav
Stats
- File size: 1008080 bytes
- AudioMetaData(sample_rate=44100, num_frames=168000, num_channels=2, bits_per_sample=24, encoding=PCM_S) Sample Rate: 44100 Shape: (2, 168000) Dtype: torch.float32
- Max: 0.330
- Min: -0.258
- Mean: -0.000
- Std Dev: 0.049
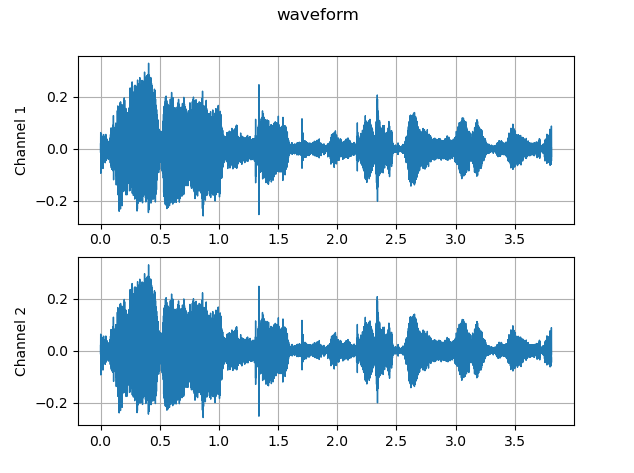
Waveform
def waveform(waveform, sample_rate, title=None, save=False):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
time_axis = torch.arange(0, num_frames) / sample_rate
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].plot(time_axis, waveform[c], linewidth=1)
axes[c].grid(True)
if num_channels > 1:
axes[c].set_ylabel(f"Channel {c + 1}")
figure.suptitle("waveform")
plt.show(block=False)
if save:
figure.savefig(Util.create_plot_path(title=title))import torchaudio
waveform, sample_rate = torchaudio.load(AUDIO_SAMPLE_FILE)
Visualization.waveform(waveform, sample_rate=sample_rate, title=AUDIO_FILE_TITLE, save=True)Spectogram
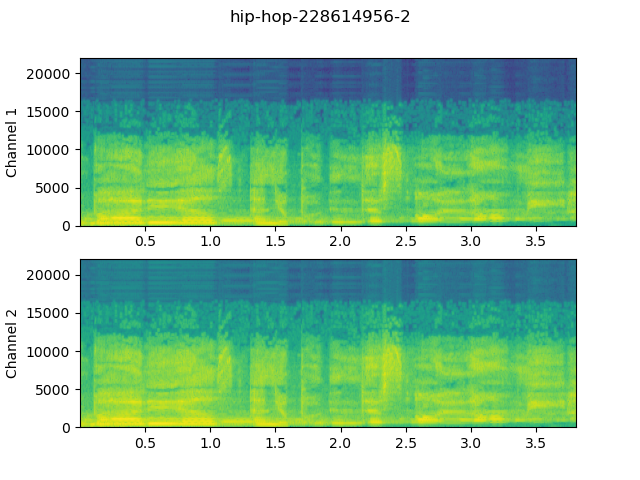
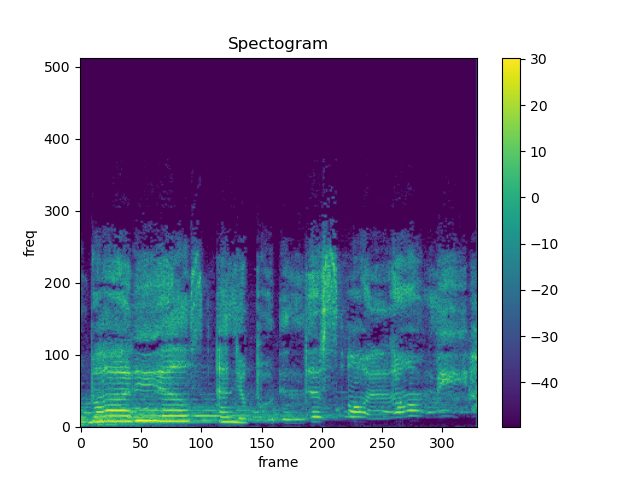
Spectogram of 2 channels with 44100 sample rate
Torchaudio feature extraction
Mel Spectogram
MelSpectrogram for a raw audio signal
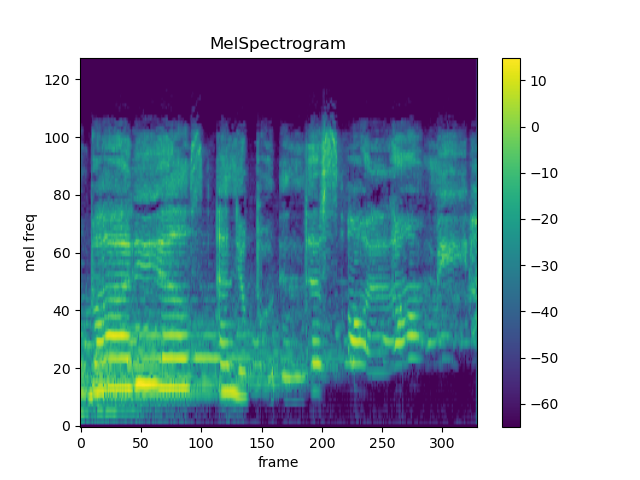
mel spectogram parameters
n_fft = 1024
win_length = None
hop_length = 512
n_mels = 128MFCC
Mel-frequency cepstrum
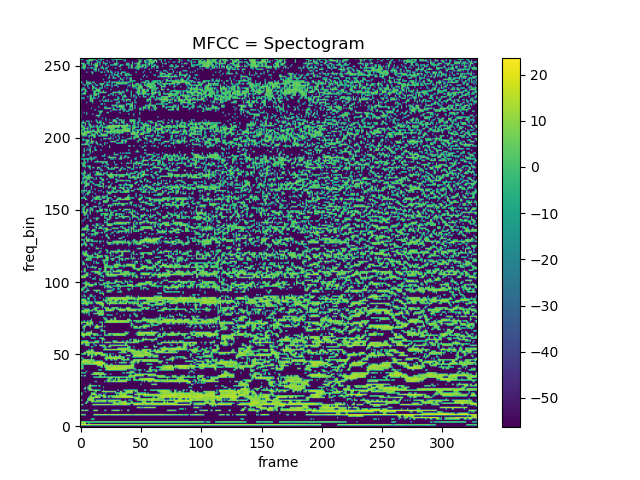
MFCC spectogram parameters
n_fft = 2048
win_length = None
hop_length = 512
n_mels = 256
n_mfcc = 256MFCC is the widely used technique for extracting the features from the audio signal, and is often used for speach recognition.
LFCC
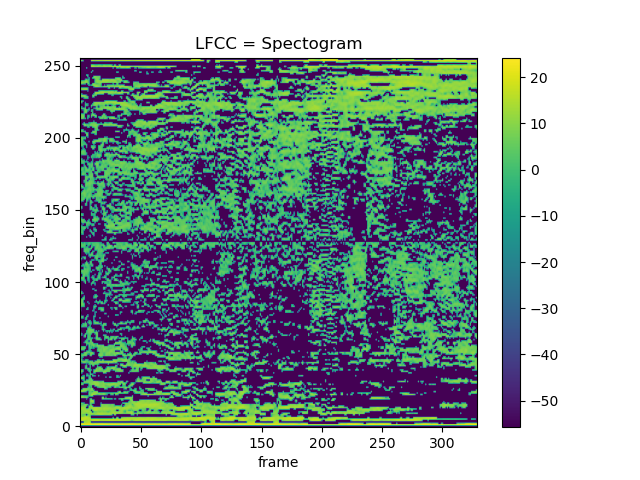
LFCC spectogram parameters
n_fft = 2048
win_length = None
hop_length = 512
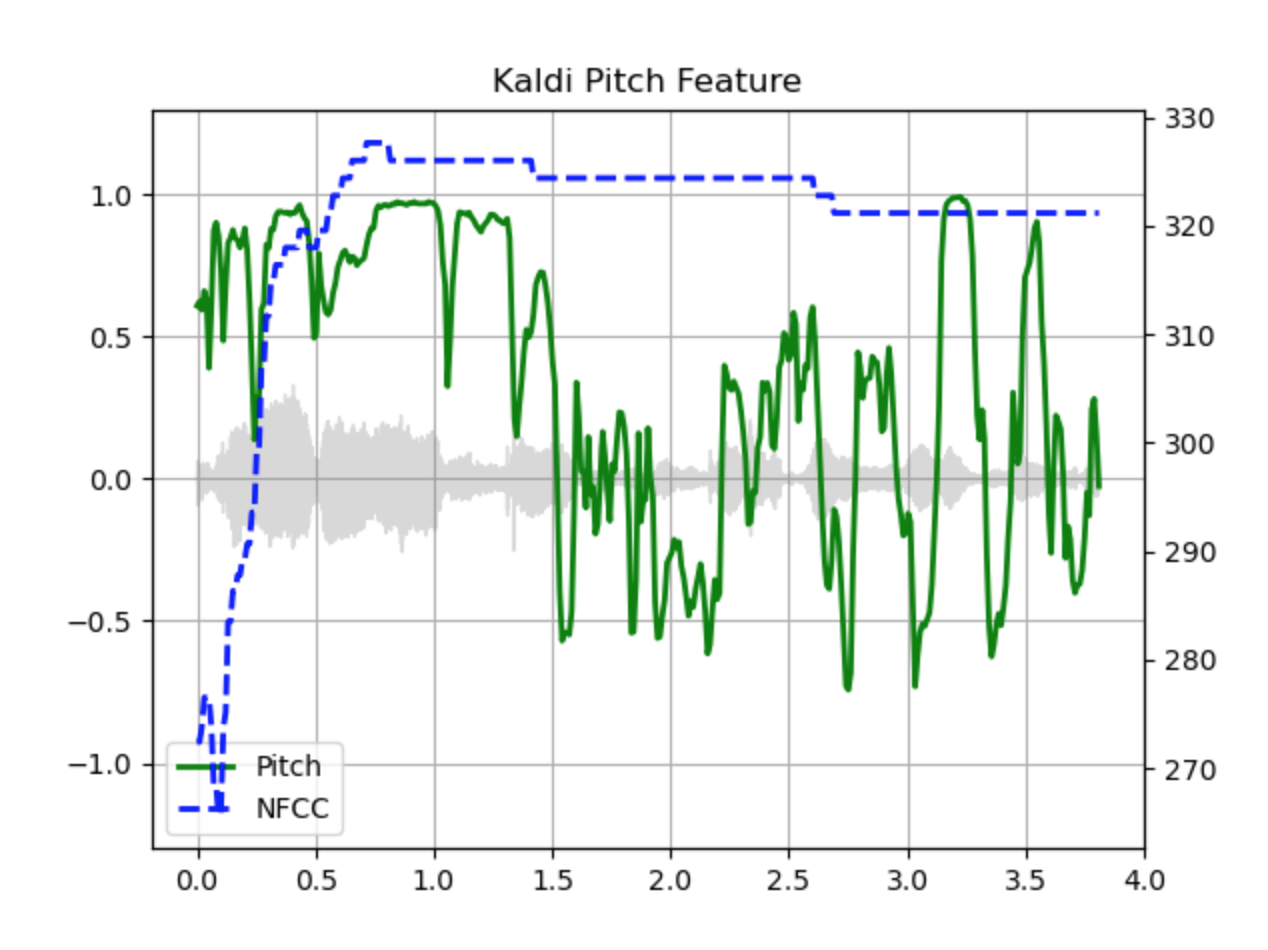
n_lfcc = 256Pitch
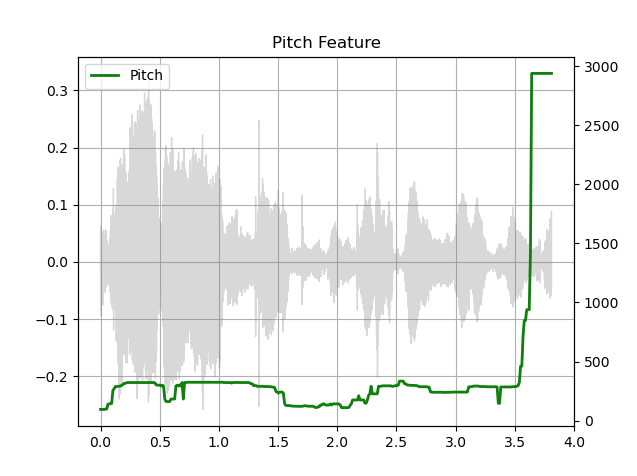
Kaldi pitch with NFCC
Pitch feature [1] is a pitch detection mechanism tuned for automatic speech recognition (ASR) applications. This is a beta feature in torchaudio, and it is available as torchaudio.functional.compute_kaldi_pitch().
Sample #2