Performance
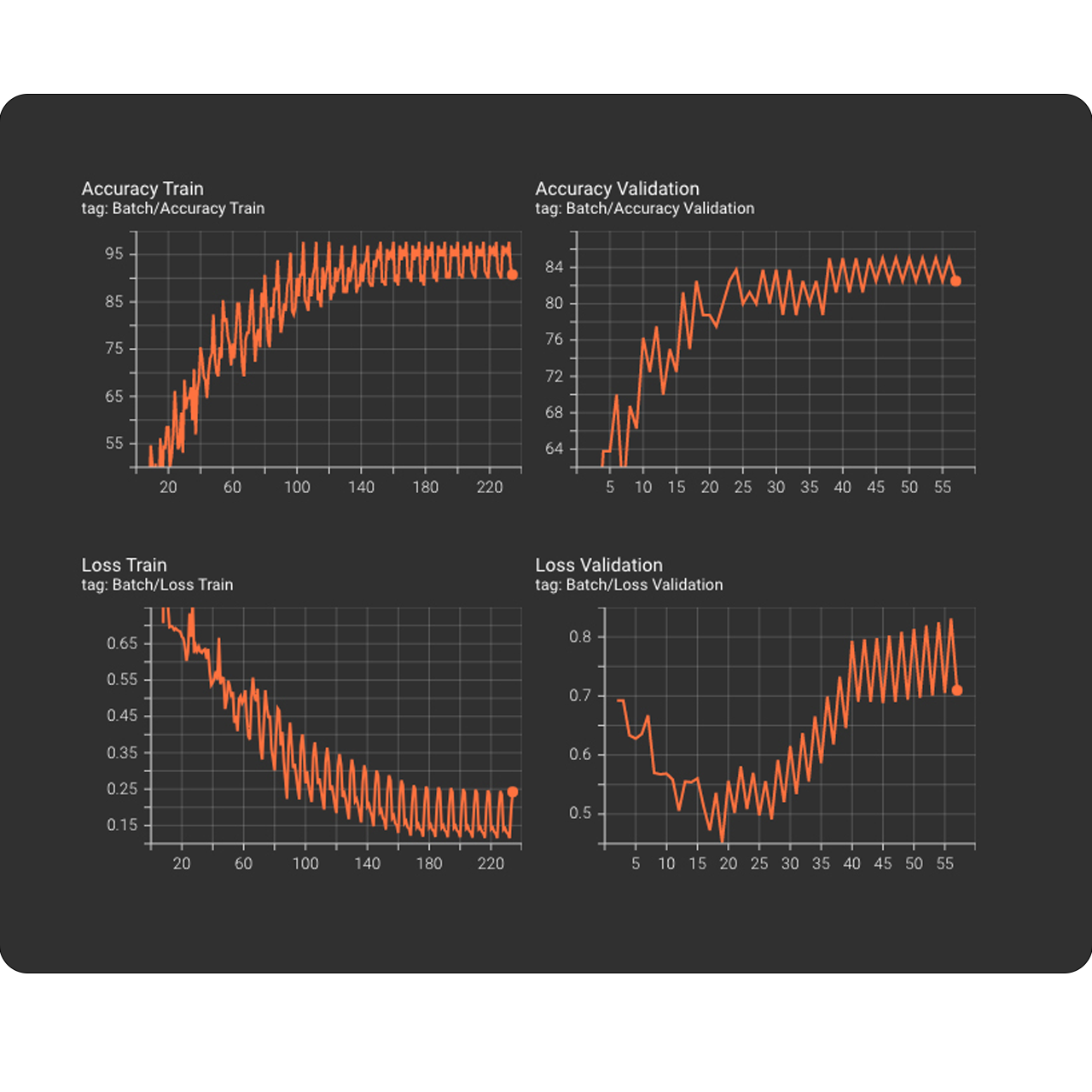
From the measurement results of the experiments confirm that different parameterizations in the CNNs as well as in the transformation of the input data affect the result.
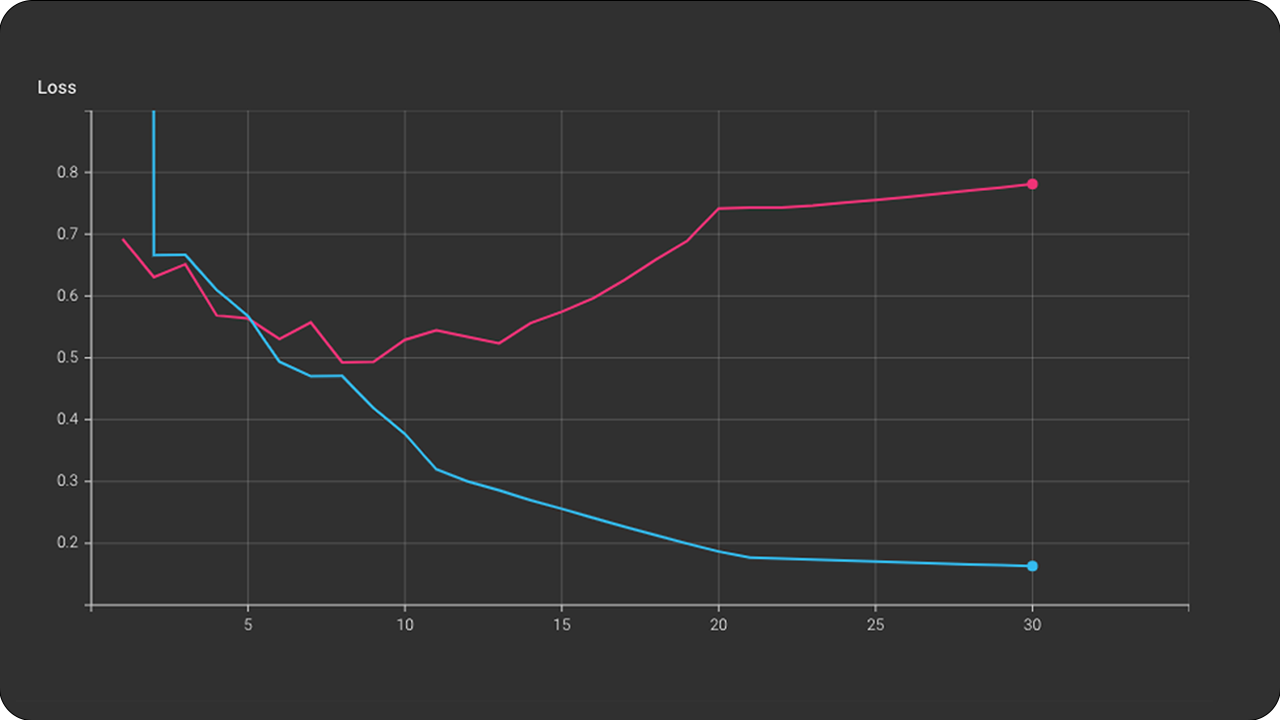
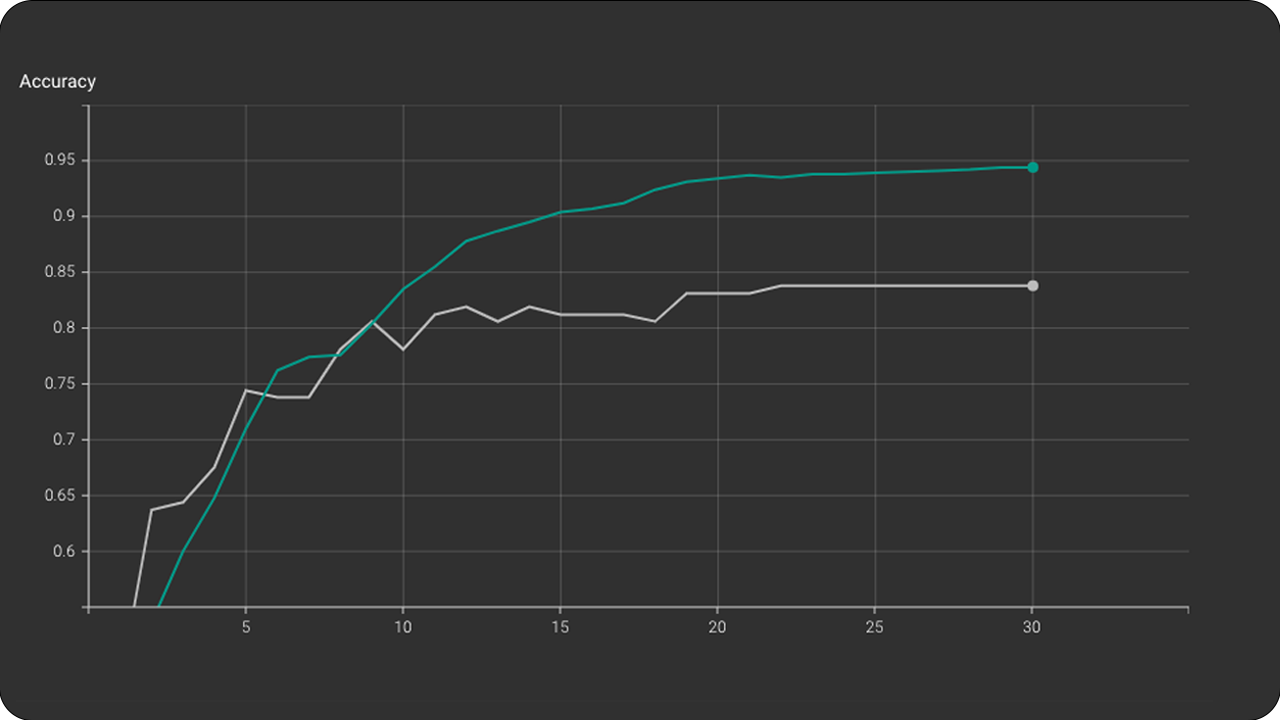
The size of the input data as seen in the first experiments greatly affects the training process. This fact is confirmed in the first experiments in which the accuracy and the loss curve stopped dropping around the middle of the experiment. Also, the depth of the network played a very important role. As we saw the VGGish architecture performed much better than CNNNetwork. In the case of VGGish the model stopped learning much later than CNNNetwork. Therefore depth enables CNN to identify many more features from the input variables and reach a higher score. Another parameter is the duration of each audio file as an input variable to CNN. The first experiments use 1 second audio files as input. This decision was made to confirm that even for 1 second my model has the ability to learn. Even if 1 second is not enough for the human auditory perception to recognize and interpret music, CNN showed the opposite even with a small accuracy rate of 71%. The latest experiments were conducted with a duration on digital music files of 5 seconds. It was shown how the duration of each music track combined with a deep CNN modulation yielded the best performance rate of all.
Loss & Accuracy
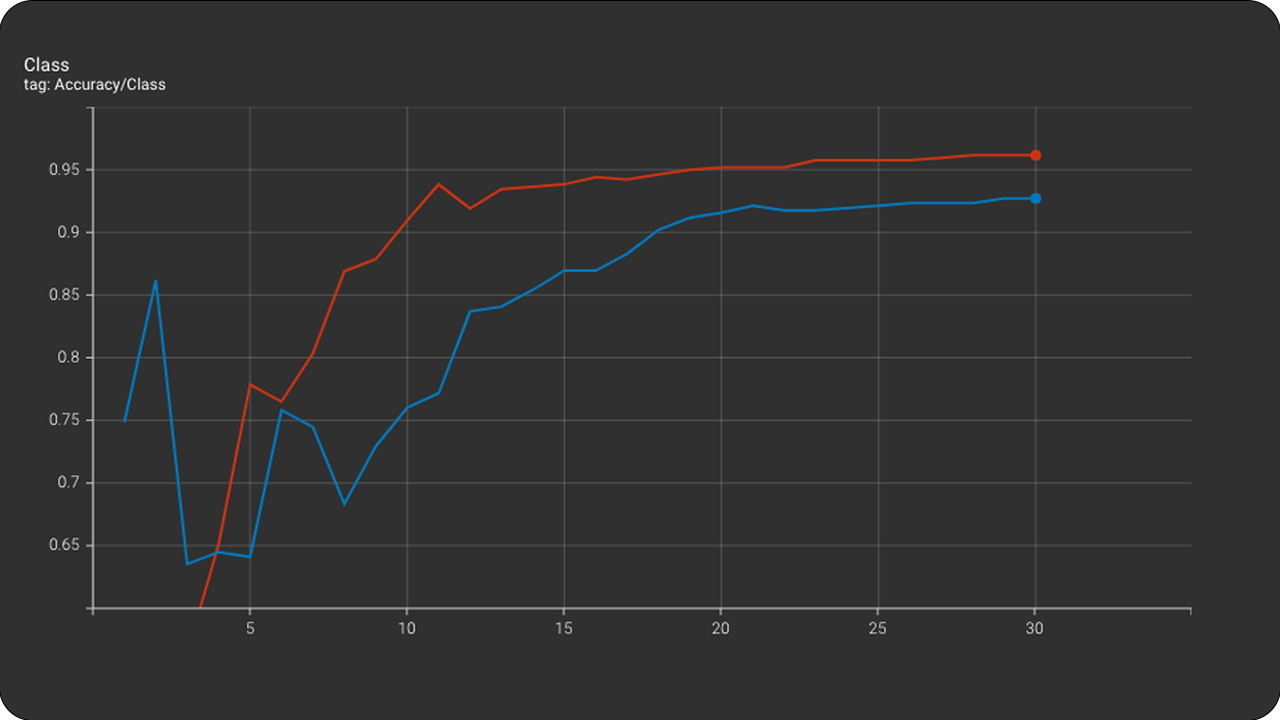
Accuracy pre class
Batch performance
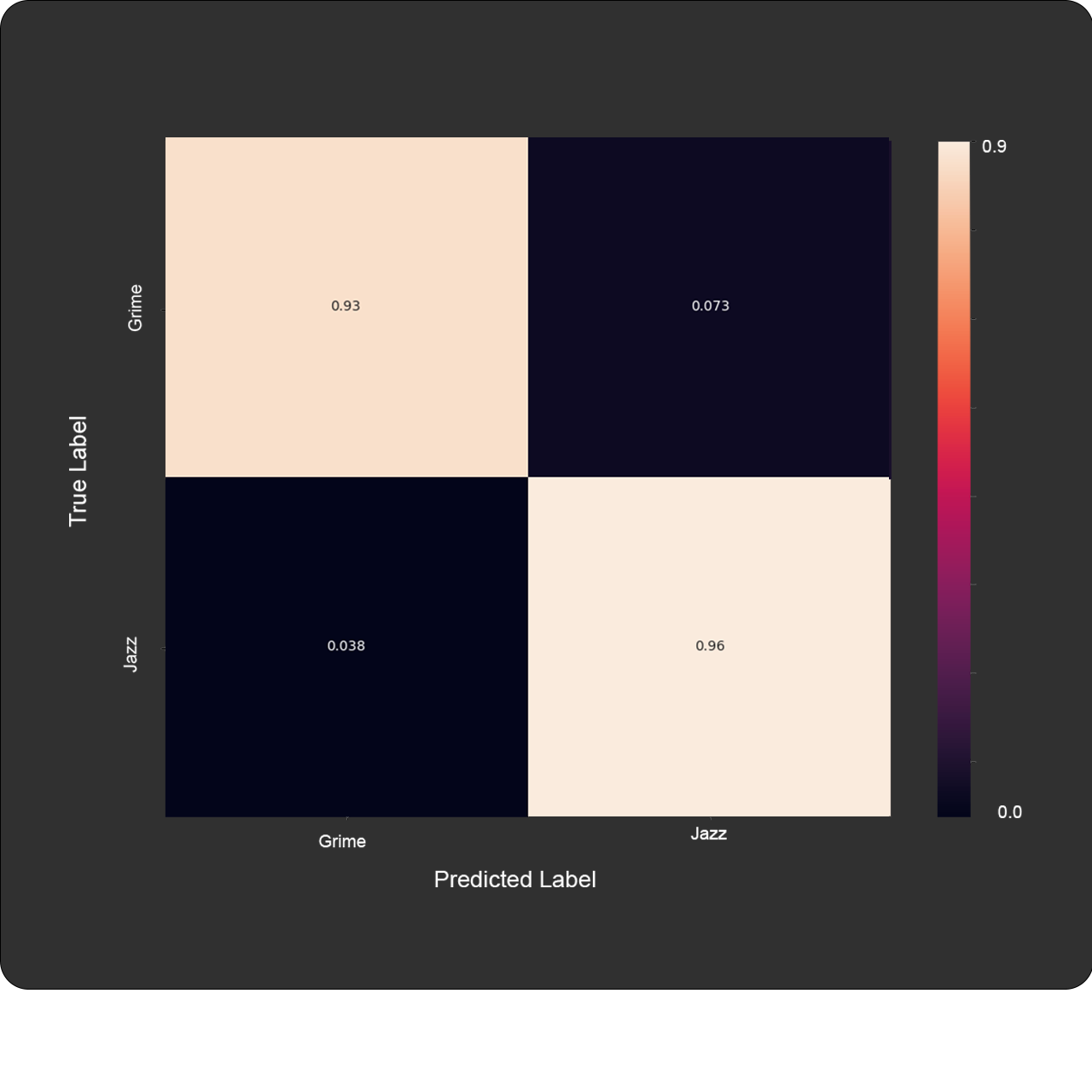
Confusion Matrix